Code Smells
I’ve mentioned code smells in this blog before, but to recap, a code smell is a warning sign that you might be looking at bad code (for some value of bad). Code smells are more like red flags than errors. Some classic example of code smells are very long functions, lots of global variables, and goto statements. There are places where all of these make sense, but in general if you see them you wonder if the code could use some work.
In most languages there is a way to take a string of characters and execute it as if it were code. Those functions (or keywords, or methods) are generally considered to be risky, because you are giving up some control over what code is run. If the input is somehow compromised, your program will have become an attack vector. Not a good place to be.
SQL Injection
A classic example of this is building SQL statements from input and including parameters in the string. If you don’t use SQL-language parameters, you are open to a SQL-injection attack where a malicious user puts characters in the input which cause the SQL statement you’re building to include instructions you didn’t intend to execute. SQL-injection is a well-understood attack and the mitigation is also well-known. Using real parameters instead of string building is the answer.
Back to PowerShell
The cmdlet which PowerShell includes to allow you to execute a string as code is Invoke-Expression. It’s pretty simple to show that it’s vulnerable to an injection attack. Consider the following code, where the intent is to write “hello ” followed by the value of a variable.
$prm1="world';get-date #"
invoke-expression "write-host 'Hello $prm1'"
You can see that the expression that is being invoked includes some quotes, but the input has been “crafted” to close the quotes early and to comment out the trailing quote. This isn’t a sophisticated example, but it should help illustrate the problem. An attacker, by the way, wouldn’t be satisfied with outputting the date either.
What to do instead?
I had been thinking about this for a while, and a few days ago someone wrote a comment on this post about it showing the problem but not giving solutions. To be fair the article did talk about using the call operator (&) but it didn’t give a lot of details. In the remainder of this post I will give some further guidance. I don’t think that all Invoke-Expression calls can be eliminated, but this should go a long way towards a solution.
What if there are spaces in the command-line?
This one is covered in the article. The call operator (&, also called the command invocation operator) can be used to execute commands that have spaces in them:
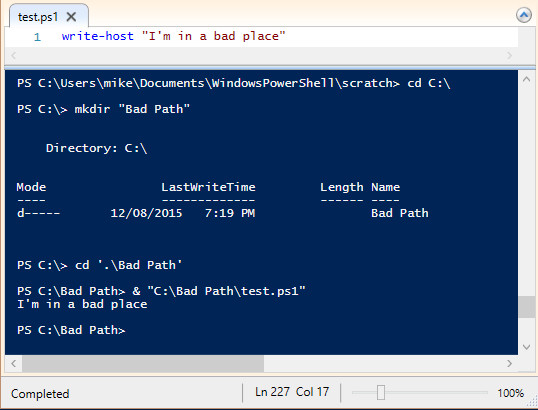
The call operator takes the name of the command, not an arbitrary string, so injection doesn’t work here:
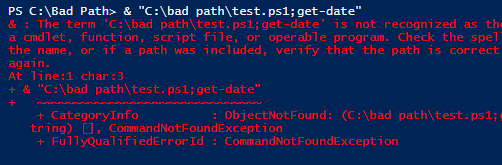
As noted in the help (about_operators), the call operator does not evaluate the string, so it can’t interpret arguments. If you need to pass arguments to parameters, you can list them after the command like this:
PS C:\Bad Path> & "get-date" 10/10/10
Sunday, October 10, 2010 12:00:00 AM
You can also pass a command (the output of get-command) to the call operator, so get-command can be an easy way to “validate” the value that is being used. If get-command doesn’t return anything, it’s not a valid command.
What if I don’t know what the command needs to be?
This is a common question. If I don’t know what command needs to be executed at the time I write the script, I can’t include it, right? Actually, there’s no reason you have to know it beforehand.
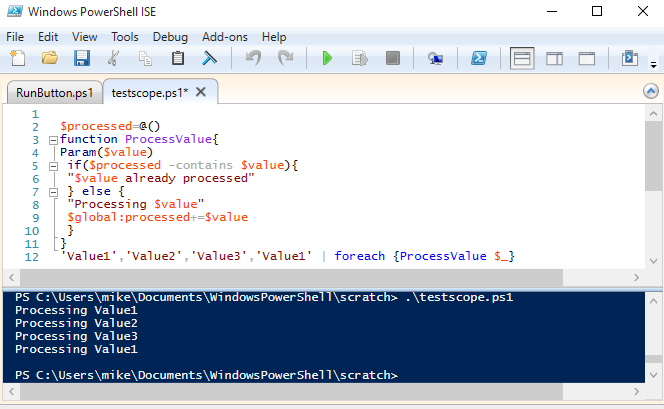
$choice=read-host "Process or Service"
if ($choice -in 'process','service'){
$cmd=get-command "get-$choice"
& $cmd
} else {
write-host 'You entered an invalid command'
}
What if I don’t know the argument values?
This one is simple. Use variables. This is bread-and-butter PowerShell.
What if I don’t know which parameters will be receiving arguments?
If you don’t know which parameters will be presented arguments, you might think you’re stuck. You could have a bunch of if/elseif/else statements trying to check each combination of parameters and include different command-lines with each, but that’s obviously (I hope) not a maintainable solution. A much better solution is to use splatting, a technique that lets you use a hashtable (or array) to supply the parameters and arguments for a command.
If the command is a PowerShell command (cmdlet, function, script), you can build a hashtable with the parameters (names) and arguments (values) you need to pass. Using a hashtable in this way is very similar to the parameter solution for SQL-injection. Because the values are bound to parameters by the engine rather than by evaluating a string, you don’t leave room for an attacker to compromise the command-line. A simple splatting example might look like this:
$parms=@{}
if($IncludeSubdirectories){
$parms['Recurse']=$true
}
if($path){
$parms['Path']=$path
}
get-childitem @parms
Note that when we splat the hashtable (doesn’t that sound nice), we use the splat operator (@) instead of the dollar-sign ($) usually used with variables.
What if I don’t know the command or the parameters?
The call operator works fine with splatting. Feel free to combine both techniques. Proxy functions, for example, use the call operator (against the original command) with $PSBoundParameters to “forward” arguments to the original command.
Conclusion.
With the call operator and splatting in your toolbox, there should be a lot less occasions that you’re tempted to use Invoke-Expression. PowerShell gives so many solid language features, it makes it easy to write good code.
What are your thoughts? Can you think of circumstances that would still require Invoke-Expression? Let me know in the comments.
–Mike