After an emergency at my previous webhost, I’ve switched to a new webhost. If you see any missing content, let me know!
Dude, Where’s my Command?
The Dilemma
This post was inspired by a recent occurrence at work. I have built a framework which constructs documents based on a lists of functions in a module specific to that kind of document.
I found myself running into an issue where even though I knew there was a command named a certain thing, and that the function was correctly exported from the module, PowerShell wasn’t finding the command.
My code looked something like this:
$module='Module1'
$Steps='Get-CustomerData','Get-MarketingData','New-CustomerMarketingDocument'
# each function takes a hashtable as a parameter and outputs a hashtable
$state=@{}
foreach($Step in $Steps){
$stepCmd=Get-Command -Name $step -module $module
$state=& $StepCmd -state @State
}
So why was PowerShell not working nicely for me? The problems has to do with how PowerShell loads functions. Let’s take a step back
PowerShell’s Command-Loading Procedure
For now, let’s assume we have a simple script module called Module1.
For a script module to be “discoverable” by PowerShell, it must exist in one of the folders listed in the PSModulePath environment variable.
This PowerShell will show you the folders that PowwerShell will look in:
$env:PSModulePath.Split(';')
Here are the results from a PowerShell 7 instance:
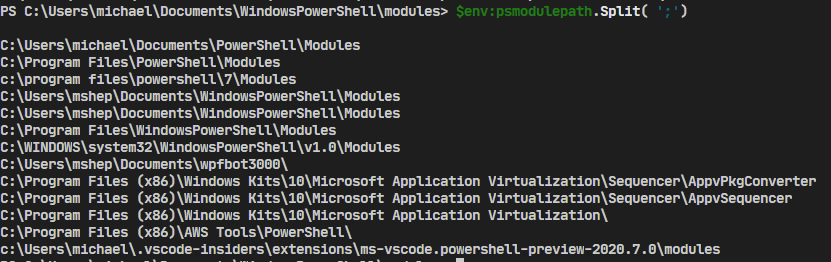
When you try to run a command (or use Get-Command), PowerShell will first look to see if the command is already loaded. IF so, then it just runs (or outputs) the command you asked for.
If it isn’t already present, PowerShell looks through valid modules for the function. As a reminder, valid modules:
- Exist in one of the folders in PSModulePath
- Have a “module file” named the same as the folder it’s in (for instance, module1\module1.psm1)
- Module Files extensions are psm1, psd1, dll, or cdxml.
- File is syntactically valid and not blocked
If the command is present, and exported (via Export-ModuleMember and Functions/CmdletsToExport in the manifest), then the module will be loaded silently and the command (now present) will be executed or output.
Pretty simple, right?
In my case, I had a valid module, in a valid folder, in the PSModulePath, with the named function exported from it. What could have gone wrong?
PowerShell Command Hiding
The problem was that I had gotten used to naming functions somewhat generically, and had duplicated one.
I had two modules which contained a function called Get-DocumentData. The command discovery procedure worked fine, it just found the wrong command.
Let’s see an example of what I’m talking about.
Consider two modules, module1 and module2.
Module1 has a single command, Get-Stuff
function Get-Stuff{
'in module1'
}
Similarly, Module2 has a Get-Stuff command which outputs ‘in module2’.
If I were to open a new PowerShell session and type Get-Stuff, PowerShell would find module1’s copy of Get-Stuff first and load it (that is, module1).
If that were the only Get-Stuff, the story would be over.
In this case, I have two different modules with Get-Stuff functions.
To get to the second, I can import the module explicitly:
Import-Module module2
You can verify the output below:
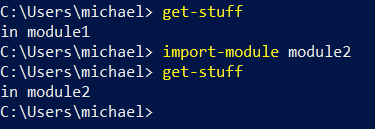
Now, we’ve imported both modules and executed both functions. What does Get-Command tell us?

First, it only shows us the command from module2, that is, the most recently loaded.
If we ask for the command from module1, we won’t find it:

You might notice that the error is misleading. There sure is a Get-Stuff command available, just not from module1 (or at least not available from module1).
But if we ask for “all” Get-Stuff commands, there it is:

So, why didn’t Get-Command show it?
The answer (which you can read in more detail here) is that the module1 version of the command has been hidden, and Get-Command (without -All) shows commands that aren’t hidden.
Adding -All to our earlier search for the command works like we had expected:

Note that there’s another way to get a module-specific command, and that’s by using a fully-qualified command reference like module1\get-stuff:
![]()
I beat my head against this one for quite a while. I was even considering writing a blog post about it when I read the about_command_precedence help topic (for research) and figured out the “issue”.
Thanks for reading,
Mike
Git – The 5 Percent that I Always Use
![]() One of the reasons I got into IT was that I really enjoy learning new things. Unfortunately, there are so many things to learn that it’s easy to get overwhelmed. Does it make sense to do a deep-dive into each technology that you use, or does it sometimes make sense to skim the cream off the top and move on to the next technology?
One of the reasons I got into IT was that I really enjoy learning new things. Unfortunately, there are so many things to learn that it’s easy to get overwhelmed. Does it make sense to do a deep-dive into each technology that you use, or does it sometimes make sense to skim the cream off the top and move on to the next technology?
In this post, I’m talking about git, the distributed source control system that is used in GitHub, Azure DevOps Repos, GitLab, and countless other places. Git can be really complicated, and intimidating, so I’m going to try to convey the tiny fragment of git which allows me to get my work done.
Just Eight Commands
Here are the commands I regularly use:
- git clone
- git checkout
- git add
- git commit
- git push
- git pull
- git branch
- (occasionally) git stash
That’s it. Eight commands.
Here’s how I do things. If you’re a git guru and see ways to improve this simple workflow, let me know. Also, know that I’m usually working on projects by myself, but I try to work like I would on a team.
Starting Off
To start, I clone the repository that I’m going to be working on. For instance, if I wanted to work on WPFBot, I’d go to the github repo for it and get the URL:
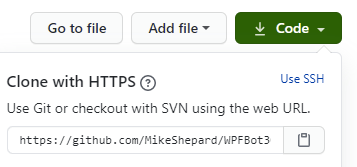
With that, I can issue the command:
git clone https://github.com/MikeShepard/WPFBot3000
and git will copy the remote repository into a local directory called WPFBot3000 ready for me to edit.
If I’m starting a new project, I would create a repo (Github, AzureDevops, etc.) and clone it locally.
I could create it locally and push it up, but this way I only have one method to remember.
Preparing for changes
Before I make any changes, I need to make sure I’m on a branch dedicated to my changes.
If this is a new set of changes I’m working on, I can create the branch and switch to it with the command:
git checkout -b BranchName
(where BranchName is a descriptive label for the changes I’m making.
If the branch already exists,
git checkout BranchName
will switch me to the existing branch.
Making Changes
Making changes is easy. I just make the changes. I can edit files, move things around, delete files, create folders, etc.
As long as the changes are in the repo (the WPFBot3000 folder, in this case), git will find them.
There are no git commands necessary for this to happen.
Staging the Changes
I tell git that I’ve made changes that I like using the command
git add .
This says to “stage” any changes that I’ve made anywhere in the repo.
Staging changes isn’t “final” in any way. It just says that these changes are ones I’m interested in.
As before, I could use sophisticated wildcards and parameters to pick what to stage, but by working on short-lived branches I almost always want to stage everything I’ve changed.
Committing the Changes
Committing the changes is like setting a milestone. This is a point-in-time where the state of these files is “interesting”.
I do this using the command: git commit -m ‘A descriptive message about what changes I made’
A few things to note about commits:
- Interesting doesn’t always mean finished. I can commit several times without pushing the code anywhere.
- “descriptive” is subjective. There has been a lot written about good commit messages. Mine probably are bad.
Repeat the Cycle
If I’m not done with the changes, I can continue the last 3 steps:
- Making Changes
- Staging the Changes
- Committing the Changes
All of these steps are happening locally, but by committing often I have chances to roll-back to different places in time if I feel like it (I rarely do).
Completing the Changes
The next step is a bit of a cheat.
I hate remembering long git commands, so rather than remembering how to link my local branch with the remote repo, I simply say
git push
Git will reply with an error message because it doesn’t know what remote branch to push it to.
In the error message, though, it tells me how to do what I want:

In this case, it’s
git push –set upstream origin TEst (and yes, branch names are case-sensitive)
Pull Request
At this point, I go to Azure DevOps or GitHub (I don’t use GitLab much) and browse to the repo.
It will usually have a notice that a branch was just changed and will give me the opportunity to create a pull request.
A pull request is a request to merge (or pull) changes from one branch into another.
Typically, you’re merging (or pulling) changes from your branch into master.
Once you’ve created the pull request, this is the time for your team members to review the changes, make suggestions, and approve or deny the request.
If you’re working alone, you can approve the request yourself.
I also select the “delete the branch after merge” option so I don’t have a bunch of old branches hanging around.
If the merge is successful, then the changes are now part of the master branch on the remote repo.
They are only in my feature branch locally, though.
Pulling Changes Down
To get the updated master branch, I have to first switch to it:
git checkout master
Once I’m on the branch, I can
git pull
to pull the changes down.
Cleaning up and Starting over
Now that our changes are in master, I can remove the local branch with:
git branch -d BranchName
At this point, I don’t usually know what I’m going to work on next.
I have a bad habit of accidentally making changes in master locally, though so my next step helps me avoid that.
I simply check out a new branch called Next like this:
git checkout -b Next
Note: This is exactly what we did at the beginning, just with a temporary branch name of Next.
When I’m ready to work on a real set of changes, I can rename the branch with
git branch -m NewBranchName
Summary
That probably seemed like a lot, but here are all of the commands (with some obvious placeholders)
- git clone <url>
- git checkout -b BranchName
- git add .
- git commit -m ‘Fantastic commit message’
- <repeat add/commit until ready to push>
- git push (followed by copy/paste from the error message)
- <proceed to create and complete the pull request>
- git checkout master
- git pull
- git branch -d BranchName
- git checkout -b Next
Bonus command – git stash
If I find I’ve made changes in master, git stash will shelve the changes. I can then get on the right branch and do a git stash pop to get the changes back.
With the adoption of the git checkout -b Next protocol, though, I don’t find myself needing this very often.
What do you think? Does this help you get your head around using git?
Very Verbose PowerShell Output
Have you ever been writing a PowerShell script and wanted verbose output to show up no matter what?
You may have thought of doing something like this:
#Save the preference variable so you can put it back later $saveVerbosePreference=$VerbosePreference #Override the preference variable to make the output show up $VerbosePreference='Continue' Write-Verbose 'This is an important message you need to see' #Leave it like you found it $VerbosePreference=$saveVerbosePreference
If you do that, you’ll get the verbose message every time, just like you wanted.
Fortunately for you, there’s a much easier way to get the message:
#By adding the -Verbose switch, you override the preference for this cmdlet Write-Verbose 'This is an important message you need to see' -Verbose
Wasn’t that easy?
A PowerShell Parameter Puzzler

I ran across an interesting PowerShell behavior today thanks to a coworker (hi Matt!).
It involved a function with just a few arguments. When I looked at the syntax something looked off.
I am not going to recreate the exact scenario I found (because it involved a cmdlet written in C#), but I was able to recreate a similar issue using advanced functions.
So consider that you are entering a command and you see an intellisense prompt like this one:
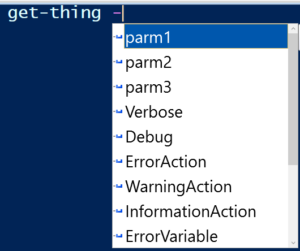
You would rightfully assume that it had 3 parameters.
If you looked at the syntax using Get-Help (or the -? switch) you would see something strange:
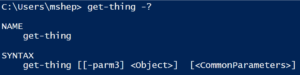
Wait…where did the other 2 parameters go?
Using Get-Command get-Thing -syntax shows essentially the same result:
![]()
This was the kind of problem I ran into. I was given a cmdlet, and when I looked at the syntax to see the parameters, I didn’t find the parameters I expected. They were there, but they weren’t shown by Get-Command.
The “puzzle” is a bit less confusing when you see the code of the function:
function get-thing {
[CmdletBinding()]
Param(
[Parameter(Position=0)]$parm1,
[Parameter(Position=0)]$parm2,
[Parameter(Position=0)]$parm3
)
#nothing to see here
}
The issue arose from the overlapping position modifiers on the parameters. When those are corrected the issue goes away.
Note: The original instance was a bit stranger. As I mentioned earlier, the cmdlet in question was written in C#. What really surprised me was that Get-Help and Get-Command showed different syntaxes. Get-Help showed all of the parameters, while Get-Command only showed the last one.
The PowerShell Conference Book

Back in May, Mike Robbins (@mikefrobbins) asked if I wanted to contribute a chapter to a book he was putting together. The book would include chapters from different scripters in the PowerShell community and each would provide material that would be similar to a session at a conference.
In addition, the proceeds from the sale of the book would support the DevOpsCollective OnRamp scholarship for new IT pros going to the PowerShell and DevOps Conference in 2019.
Sounded like fun, so I signed on. We did the writing in markdown in a private GitHub repo. Not at all what I’m used to for writing but it was a really good experience. Mike was joined by Mike Lombardi (@barbariankb, from the STLPSUG) and Jeff Hicks (@jeffhicks). They did a great job corralling over 30 writers and at this point, the book is at 90% complete.
If you haven’t heard about this, go over to leanpub and take a look. The table of contents alone should convince you that this book is worth your time.
My chapter, Rethinking PowerShell GUIs, went live last friday (8/3) and talks about the beginnings of WPFBot3000 and a “companion” module called ContextSensitiveMenus which I haven’t blogged about yet.
I would enjoy hearing feedback on my chapter and the book in general.
–Mike
PowerShell DSL Module Considerations
Just a quick note to mention a couple of things I’ve come across with PowerShell modules that encapsulate DSLs (Domain Specific Languages, specifically WPFBot3000).
PowerShell Command Name Warnings
PowerShell modules have always issued warnings if they contain commands that don’t use approved verbs. What’s fun with modules for DSLs is that the commands in general don’t use verbs at all. Since these commands aren’t “proper”, you might expect a warning. You won’t get one, though.
PowerShell Module Autoloading
PowerShell modules have had autoloading since v3.0. Simply put, if you use a cmdlet that isn’t present in your session PowerShell will look in all of the modules in the PSModulePath and try to find the cmdlet somewhere. If it finds it, PowerShell imports the module quietly behind the scenes.
This doesn’t work out of the box with DSLs. The reason is simple.
DSLs generally have commands that aren’t in the verb-noun form that PowerShell is expecting for a cmdlet, so it doesn’t try to look for the command at all.
The fix for this is simple (for WPFBot3000, at least). All I’ve done is replace the two top-level commands (Window and Dialog) with well-formed cmdlet names (New-WPFBotWindow and Invoke-WPFBotDialog). Then, I create aliases (Window and Dialog) pointing to these commands.
Now that I think of it, I’m not sure why that works. If PowerShell is looking for the aliases, why wasn’t it finding the commands? Nevertheless, it works.
That’s all for today, just a couple of oddities.
–Mike
WPFBot3000 – Approaching 1.0
I just pushed version 0.9.18 of WPFBot3000 to the PowerShell Gallery and would love to get feedback. I’ve been poking and prodding, refactoring and shuffling for the last month or so.
In that time I’ve added the following:
- Attached Properties (like Grid.Row or Dockpanel.Top)
- DockPanels
- A separate “DataEntryGrid” to help with complex layout
- A ton of other controls (DataGrid and ListView are examples)
- A really exciting BYOC (bring your own controls) set of functions
Mostly, though, I’ve tried to focus on one thing: reducing the code needed to build a UI.
To that end, here are a few more additions:
- Variables for all named controls (no more need to GetControlByName()
- -ShowForValue switch on Window which makes it work similarly to Dialog
In case you haven’t looked at this before, here’s the easy demo:
$output=Dialog {
TextBox FirstName
TextBox LastName
Calendar Birthdate
}
'{0} {1} was born on {2}' -f $output.FirstName,$output.LastName,$output.Birthdate
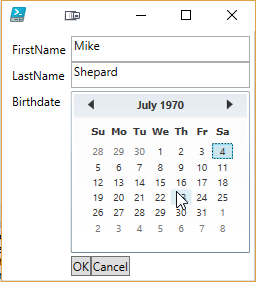

There are tons of features to talk about, and I’ll be following up with a series of posts illustrating them.
In the meantime, use Install-Module WPFBot3000 (or Update-Module WPFBot3000) and let me know what you think.
Are there things that are missing?
Are there things that are broken?
Is something difficult to do that shouldn’t be?
Feel free to enter issues in the github repo or let me know through twitter, email, Reddit, etc.
-Mike
Introducing WPFBot3000
Preamble
After 2 “intro” posts about writing a DSL for WPF, I decided to just bit the bullet and publish the project. It has been bubbling around in my head (and in github) for over 6 months and rather than give it out in installments I decided that I would rather just have it in front of a bunch of people. You can find WPFBot3000 here.

Before the code, a few remarks
A few things I need to say before I get to showing example code. First, naming is hard. The repo for this has been called “WPF_DSL” until about 2 hours ago. I decided on the way home from work that it needed a better name. Since it was similar in form to my other DSL project (VisioBot3000), the name should have been obvious to me a long time ago.
Second, the main reasons I wrote this are:
- As an example of a DSL in PowerShell
- To allow for easier creation of WPF windows
- Because I’m really not that good at WPF
In light of that last point, if you’re looking at the code in the repo and you see something particularly horrible, please enter an issue (or even better a pull request with a fix). As far as the first two go, you can be the judge after you’ve seen some examples.
Installing WPFBot3000
WPFBot3000 can be found in the PowerShell Gallery, so if you want to install it for all users you can do this:
#in an elevated session Install-Module WPFBot3000
Or, if you want to install it for the current user only, do this:
Install-Module WPFBot3000 -Scope CurrentUser
If you’d rather, you can clone the repo from github (it has examples and tests) and install it from the WPFBot3000 subfolder.
A first example
Here’s a pretty simple example that should look familiar if you read the previous posts.
Import-Module WPFBot3000
Dialog {
TextBox FirstName
TextBox LastName
TextBox EmailAddress
DatePicker ReminderDate
}
Running that shows a window like this (the gridlines are for debugging layout and they will be going away/configurable in an upcoming release):
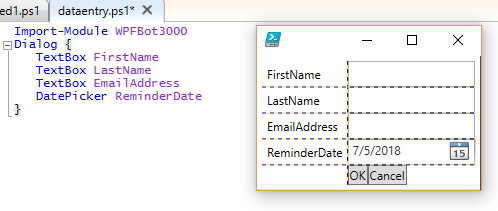
Comparing the code to the examples in the previous posts you’ll notice the main command is now Dialog rather than Window. There is still a Window command, but it just outputs the window object. The Dialog command uses Window to build the object (after adding an OK and Cancel Button) and then calls ShowDialog() on it. If the user presses OK, Dialog builds an object representing the controls in the window and outputs that object. The output object has properties that match the names of the controls* in the window:

* Only named controls that know how to return a value
You’ll also notice that DatePicker has been implemented in addition to TextBox.
The current list of controls that have been implemented is as follows:
- Button
- CheckBox
- ComboBox
- CredentialPicker
- DatePicker
- DirectoryPicker
- FilePicker
- Grid
- GridSplitter
- Image
- Label
- ListBox
- MutliLineTextBox
- Password
- StackPanel
- TabControl
- TabItem
- TextBlock
- TextBox
- TreeView
Other Features
I’m not going to go into every feature present (more posts to come), but here are some teasers:
- Context Menus
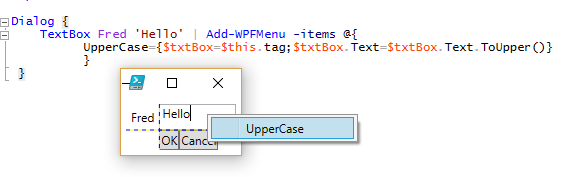
- Event Handlers
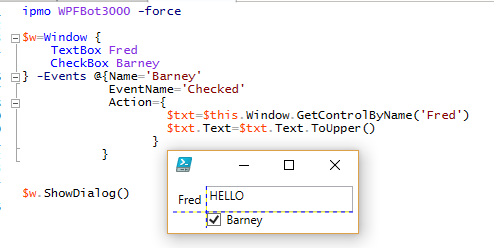
- Changing Properties (but not attached or derived properties yet)

That’s enough for tonight, but I’ll be posting more in the days and weeks to come.
Let me know what you think. Feel free to post
A PowerShell WPF DSL (Part 2) – Getting Control Values
Some Background
Before I start, I should probably take a minute to explain what a DSL is and why you would want to use one.
A DSL (domain-specific language) is a (usually small) language where the vocabulary comes from a specific problem domain (or subject). Note that this has nothing to do with Active Directory domains, so that might have been confusing.
By using words that are naturally used in describing problems in this subject, it is possible to write using the DSL in ways that look less like programming and more like describing the solution.
For instance, in Pester, you might write part of a unit test like this (3.0 syntax):
It "Has a non-negative result" {
$result | Should Be GreaterThan 0
}
There are some aspects of this that look like PowerShell (the $, the | and the {}), but in general it doesn’t look much like code. It looks more like a description of the test that we’re writing.
In the WPF DSL that I’m describing in these posts, I want to be able to write PowerShell scripts that create WPF applications in a way that the “WPF” part of the script is easy. At least, a lot easier than trying to generate XAML or automate the WPF classes using brute force. That being said, the code in my DSL is not some sort of magic, it’s just PowerShell code.
One interesting aspect of DSLs is that because they don’t look quite like code, they often ignore coding conventions. Note that the Pester example had a PowerShell cmdlet called “It”. No verb-noun convention followed there. Also, Using positional parameters is more common in a DSL. Not a problem, just something to be aware of.
Getting Control Values
One of the problems I listed at the end of the previous post (#3) was that reading the text property won’t work once we have other controls to think about besides textboxes.
My solution here has worked out really well. I decided to add a method to any control that I would want to get a value from. The method is called GetControlValue. It is responsible for knowing how to get the values from the control (which, as part of the control object it will have no problem with).
Here’s the updated Textbox function:
function TextBox {
[CmdletBinding()]
Param($Name)
$Properties = @{ Name = $name ;MinWidth=100}
New-Object System.Windows.Controls.TextBox -Property $properties |
Add-Member -Name GetControlValue -MemberType ScriptMethod -Value {$this.Text} -PassThru
}
Since it’s a ScriptMethod, we get to use $this to refer to the control, so $this.Text is the value we want.
With that in place, we need to update the If statement at the end of the Window function to use the ScriptMethod. Here’s what it looks like:
if($window.ShowDialog() -or $true){
if($window.ShowDialog() -or $true){
$output=[Ordered]@{}
foreach($item in $controls){
$output[$item.Name]=$item.GetControlValue()
}
[PSCustomObject]$output
}
Conclusion
Here’s the checklist now:
- Only textboxes? Need several other controls
- OK/Cancel
With other controls, reading the text property won’t be a strategy- Nested controls
- Populating controls
- Events
- ContextMenus
- Setting control properties
Stay tuned for more…
–Mike